Cloud storage - never fails to surprise #2 - Cloud dorks
The last post allready showed some ideas to gather sensitive files from public cloud ressources.
And yeah, it got worse…
To identify most of the stuff, we are almost exclusevly using https://grayhatwarfare.com/
| ⠀ | ⠀ |
|---|---|
 |
 |
 |
 |
 |
 |
I had the feeling that one FacePalm is not enough
Intro
Recently on my Twitter (yes it is Twitter, not X!) timeline, there was a tweet with github dorks.
So far nothing really special, but this brought up the idea to make also some cloudstorage dorks and some quick checks showed that it is devastating.
Now you might say, not again, thats boring, thats okay and up to you, it is what it is.
 Github Dorks from @therceman
Github Dorks from @therceman
Due a quick tip of @rootcathacking for a simpe OCR, we can use PowerToys Text Extractor to avoid typing all those values.
Another interesting read is https://www.sentinelone.com/labs/cloudy-with-a-chance-of-credentials-aws-targeting-cred-stealer-expands-to-azure-gcp/ as it offers a nice table what ransomwaregroups are looking for.
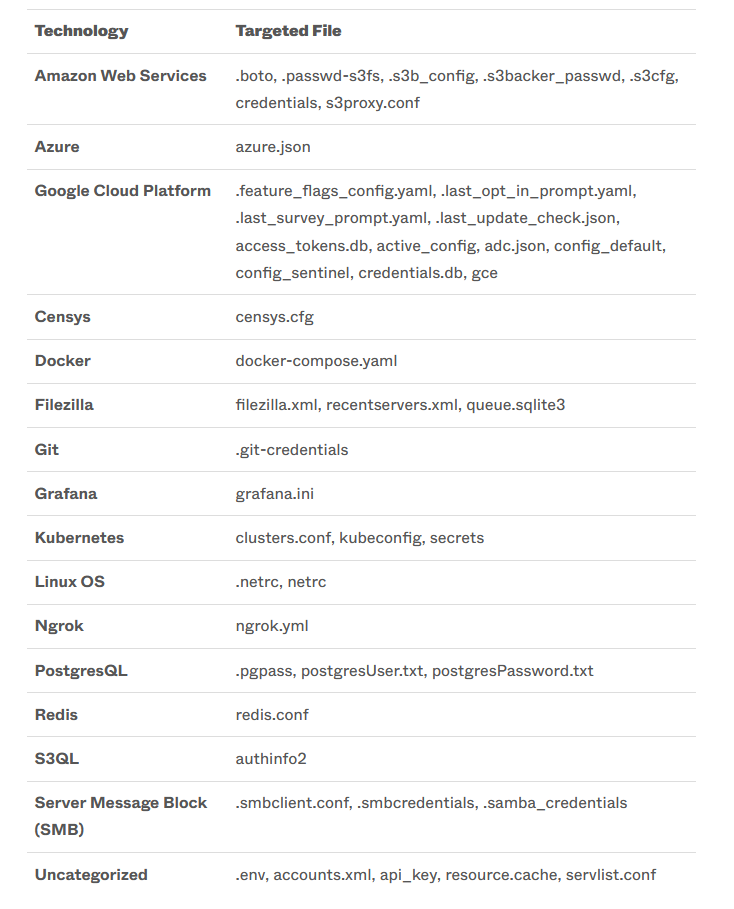 Table with sensitive files
Table with sensitive files
Build some dorks
To design some queries, we can either use GUI queries or directly jump to the API.
URLs for the api only have a /api/v2 and a authentication header in it, so I will just keep to the api version.
https://buckets.grayhatwarfare.com/files?keywords=wp-config%20-sample&order=last_modified&direction=desc&extensions=php&start=0&limit=500
curl --request GET --url \
'https://buckets.grayhatwarfare.com/api/v2/files?keywords=wp-config&order=last_modified&direction=desc&extensions=php&start=0&limit=500' --header 'Authorization: Bearer #####' | jq | grep "url" | cut -d ":" -f 2- | sed 's/,//g' | xargs -i wget --no-check-certificate {}
As some companies / tools / people tend to use existing file extensions for other stuff it might be a good idea to quickly check it, e.g. via filesize and exclude those buckets. Nobody want several gigabytes of textures, because somebody named then x.env.
Another little trick is to add some stop words. Typically you can immediately skip files which contains words pointing to the default files, like example, sample, samples. Stopwords are provided with ` -word` for the keyword.
If you have an enterprise license for GrayHatWarfare you can also go for the regex, which should even improve it.
Sample
We need to determine the amount of results, as we can max get 1000 entries per query.
curl --request GET --url 'https://buckets.grayhatwarfare.com/api/v2/files?keywords=%20-sample%20-example%20-samples&order=last_modified&direction=desc&extensions=env&start=0&limit=1000' --header 'Authorization: Bearer #####' | jq '.meta.results'
23627
So we would need to make this in 24 requests if we want all data. We can either store the urls inbetween or do this directly. I would recommend to store it.
seq 0 24 | xargs -i curl --request GET --url 'https://buckets.grayhatwarfare.com/api/v2/files?keywords=%20-sample%20-example%20-samples&order=last_modified&direction=desc&extensions=env&start={}000&limit=1000' --header 'Authorization: Bearer #####' | jq -r '.files[].url' >> env_urls.txt
cat env_urls.txt | wc -l
23626
So we now have a huge list which we can download. To speed things a little bit up wen gonna use GNU parallel.
cat env_urls.txt | parallel --bar -P 10 wget --no-check-certificate {}
Dirty All in One
seq 0 24 | xargs -i curl --request GET --url 'https://buckets.grayhatwarfare.com/api/v2/files?keywords=%20-sample%20-example%20-samples&order=last_modified&direction=desc&extensions=env&start={}000&limit=1000' --header 'Authorization: Bearer #####' | jq -r '.files[].url' | parallel --bar -P 10 wget --no-check-certificate {}
The big run
I did the following queries and downloaded the files.
https://buckets.grayhatwarfare.com/files?keywords=manifest%20-sample%20-example%20-samples&order=last_modified&direction=desc&extensions=xml&start=%7B%7D000&limit=1000
https://buckets.grayhatwarfare.com/files?keywords=travis%20-sample%20-example%20-samples&order=last_modified&direction=desc&extensions=yml&start=%7B%7D000&limit=1000
https://buckets.grayhatwarfare.com/files?keywords=WebServers%20-sample%20-example%20-samples&order=last_modified&direction=desc&extensions=xml&start=%7B%7D000&limit=1000
https://buckets.grayhatwarfare.com/files?keywords=secrets%20-sample%20-example%20-samples&order=last_modified&direction=desc&extensions=yml&start=%7B%7D000&limit=1000&excludedBuckets=us-west-2-aws-training.s3.amazonaws.com
https://buckets.grayhatwarfare.com/files?keywords=LocalSettings%20-sample%20-example%20-samples&order=last_modified&direction=desc&extensions=php&start=%7B%7D000&limit=1000
https://buckets.grayhatwarfare.com/files?keywords=config%20-sample%20-example%20-samples&order=last_modified&direction=desc&extensions=php&start=%7B%7D000&limit=1000&excludedBuckets=archiv-pdf-images.s3.amazonaws.com,varsuite-greydoor-publications.s3.amazonaws.com
https://buckets.grayhatwarfare.com/files?keywords=wp-config%20-sample%20-example%20-samples&order=last_modified&direction=desc&extensions=php&start=%7B%7D000&limit=1000
https://buckets.grayhatwarfare.com/files?keywords=credentials&start=%7B%7D000&limit=1000
https://buckets.grayhatwarfare.com/files?keywords=secret_token%20-sample%20-example%20-samples&order=last_modified&direction=desc&extensions=rb&start=%7B%7D000&limit=1000
https://buckets.grayhatwarfare.com/files?keywords=carrierwave%20-sample%20-example%20-samples&order=last_modified&direction=desc&extensions=rb&start=%7B%7D000&limit=1000
https://buckets.grayhatwarfare.com/files?keywords=database%20-sample%20-example%20-samples&order=last_modified&direction=desc&extensions=yml&start=%7B%7D000&limit=1000
https://buckets.grayhatwarfare.com/files?keywords=config%20-sample%20-example%20-samples&order=last_modified&direction=desc&extensions=yaml&start=%7B%7D000&limit=1000
https://buckets.grayhatwarfare.com/files?keywords=settings%20-sample%20-example%20-samples&order=last_modified&direction=desc&extensions=py&start=%7B%7D000&limit=1000
https://buckets.grayhatwarfare.com/files?keywords=%20-sample%20-example%20-samples&order=last_modified&direction=desc&extensions=dockercfg&start=%7B%7D000&limit=1000
https://buckets.grayhatwarfare.com/files?keywords=%20-sample%20-example%20-samples&order=last_modified&direction=desc&extensions=env&start=%7B%7D000&limit=1000
https://buckets.grayhatwarfare.com/files?keywords=%20-sample%20-example%20-samples&order=last_modified&direction=desc&extensions=ovpn&start=%7B%7D000&limit=1000
https://buckets.grayhatwarfare.com/files?keywords=%20-sample%20-example%20-samples&order=last_modified&direction=desc&extensions=cscfg&start=%7B%7D000&limit=1000
https://buckets.grayhatwarfare.com/files?keywords=%20-sample%20-example%20-samples&order=last_modified&direction=desc&extensions=mdf&start=%7B%7D000&limit=1000
https://buckets.grayhatwarfare.com/files?keywords=%20-sample%20-example%20-samples&order=last_modified&direction=desc&extensions=sdf&start=%7B%7D000&limit=1000
https://buckets.grayhatwarfare.com/files?keywords=%20-sample%20-example%20-samples&order=last_modified&direction=desc&extensions=sqlite&start=%7B%7D000&limit=1000
https://buckets.grayhatwarfare.com/files?keywords=exe+-sample+-example+-samples&extensions=config&order=last_modified&direction=desc
https://buckets.grayhatwarfare.com/files?keywords=web+-sample+-example+-samples&extensions=config&order=last_modified&direction=desc
https://buckets.grayhatwarfare.com/files?keywords=dll+-sample+-example+-samples&extensions=config&order=last_modified&direction=desc
https://buckets.grayhatwarfare.com/files?keywords=env+-sample+-example+-samples&extensions=cgi&order=last_modified&direction=desc
https://buckets.grayhatwarfare.com/files?keywords=appsettings+-sample+-example+-samples&extensions=json&order=last_modified&direction=desc
https://buckets.grayhatwarfare.com/files?keywords=application+-sample+-example+-samples&extensions=properties%2Cyml&order=last_modified&direction=desc
https://buckets.grayhatwarfare.com/files?keywords=config+-sample+-example+-samples&extensions=js&order=last_modified&direction=desc
https://buckets.grayhatwarfare.com/files?keywords=tomcat-users%20-sample%20-example%20-samples&extensions=xml&order=last_modified&direction=desc&page=1&excludedBuckets=unzip-plugin.s3.amazonaws.com,maincomputer.s3.amazonaws.com
https://buckets.grayhatwarfare.com/files?keywords=-sample+-example+-samples&extensions=s3conf%2Cs3cnf%2Cs3cfg&order=last_modified&direction=desc
https://buckets.grayhatwarfare.com/files?keywords=credentials%20-sample%20-example%20-samples&fullpath=1&extensions=csv&order=last_modified&direction=desc&page=1&excludedBuckets=ntq.projects.s3.amazonaws.com
https://buckets.grayhatwarfare.com/files?keywords=creds+-sample+-example+-samples&fullpath=1&extensions=csv%2Ctxt&order=last_modified&direction=desc&excludedBuckets=ntq.projects.s3.amazonaws.com
https://buckets.grayhatwarfare.com/files?keywords=aws+-sample+-example+-samples&extensions=xml&order=last_modified&direction=desc&excludedBuckets=ntq.projects.s3.amazonaws.com
https://buckets.grayhatwarfare.com/files?order=last_modified&keywords=credentials&direction=desc&extensions=jpg,png,webp,jpeg,html,mp3,mp4,js,css,svg&extensionsMode=exclude&excludedBuckets=minikube-builds.storage.googleapis.com,strabo.s3.amazonaws.com,knowledgebase-public.s3.amazonaws.com
https://buckets.grayhatwarfare.com/files?keywords=access_tokens&extensions=db&order=last_modified&direction=desc&excludedBuckets=ntq.projects.s3.amazonaws.com
By doing some grepping and also using trufflehough I found:
- 185 AWS keys (AKIA#######) from them at least 45 Keys have been valid. From the valdi tokens several user had access to the IAM, at least one was directly a full administrator. I reported them to AWS.
- 3 GCP service accounts
- Several working OpenVPN Configurations lacking a password
- Multiple valid API Keys for mailchimp, mailgun and sendgrid
Actions
I tried to talk to the AWS support about the leaked keys, which was quite difficult, as they did not understand, that I am not careing about my own account here. So I sent 45 sets of AWS credentials to them, let’s see what will happen.